In the previous article, I explained the importance of data cleaning and preprocessing in machine learning projects and the problem and challenges that may occur when we don’t have proper data pipeline orchestration. In the previous article, I also explained how to use prefects and set up prefects in docker.
Note**: Since from the previous article part 2.1 there are a lot of major updates with Prefect, In this article I will also give some of the updates that I have changed the code to fit with a new version of Prefect (the latest version when I am writing this prefect=3.0.5)
1. Some updates of services set up in docker
Dockerfile of Prefect Updated
Docker-compose Updated
In this docker Compose I added another service for Minio, which will be used for storing static data like CSV, text, etc. that we will use in our data preprocessing workflow.
Minio: Is an object store that is comparable with Amazon S3, we can store all static files, but Minio is open source and we can deploy it in our own server.

In this article, I will continue with the process by explaining and implementing the whole cycle from reading the data until the data is ready to train by integrating it with the perfect workflow orchestration.
First, we need to ensure that all the needed services are up and working in docker containers. There are 3 services that we need to run server, minio, and database.
docker compose --profile server --profile minio up
when we use --profile server there will be 2 services up which are database and server, since database service and server service has the same profile. And when use --profile minio Minio service will be up and we will be able to store and retrieve data from Minio
You can access
- Prefect’s UI using http://localhost:4200/dashboard
- Minio UI using http://localhost:9001 and use credential in docker-compose to log into the dashboard
2. Data Preparation
Like I have described in Part 1, we will not focus on the accuracy of the model but instead, we will be more focused on machine learning workflow. We will use the data from Kaggle: https://www.kaggle.com/datasets/adammaus/predicting-churn-for-bank-customers/data

First, we need to download all bank customer churns from Kaggle as a CSV file.
After this, we need to upload and store our data in Minio to make sure that every step of our machine-learning workflow be able to access the same data from Minio

3. Data PreProcessing
Every data preprocessing step will be done in Prefect flow and task because we want to make sure that all the step of data preprocessing are independent, reuseable, and easy to schedule.
If you don’t understand Prefect you can check part 2.1 or check Prefect official documentation here.
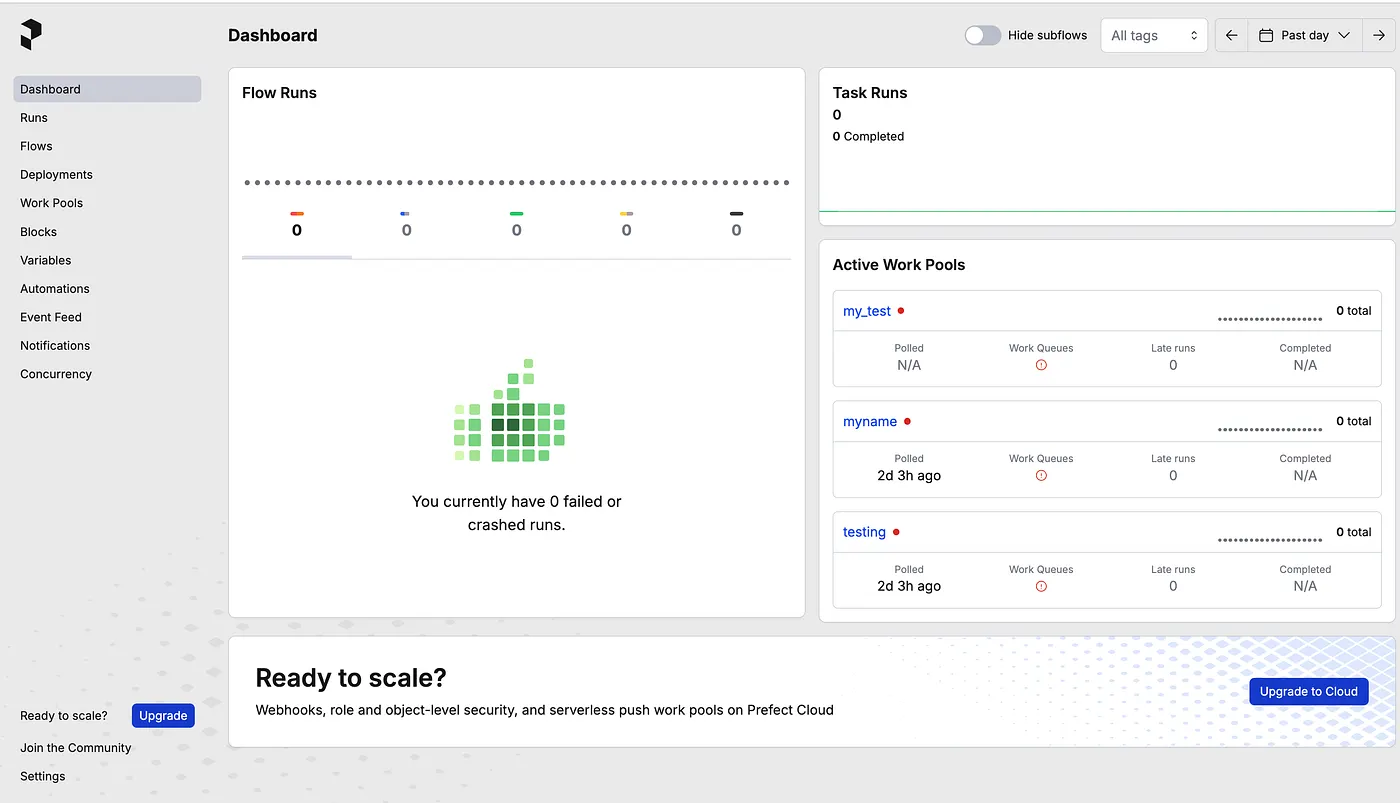
This is the Prefect’s dashboard which we can see logs, and time to run the flows and tasks and also schedule our flows and tasks from UI, If you want to learn more about all the tools in Prefect you can check the official document of Prefect: https://docs.prefect.io/3.0/get-started/index
First, we need to create some task that we want to do processing on our data
Create a file name workflow.py
In this file, we have the full workflow of our data preprocessing step, there is one main flow which is data_preprocssing and in this flow, there will be tasks such as
- get_data : to read data from Minio as pandas dataframe
- df_fill_age_missing : to fill the missing age of customer data with mean or medium base on the value we pass from the flow
- encode_category_feature : this task is to encode the category feature to a numeric value to make sure we can train the model based on that value
- scale_numberic_feature: This task is use to scale all the numeric feature to make sure that all the feature has the same value range, this will improve the overall accuracy of the model.
- upload_to_minio : After finish all the processing steps we will upload the final data to Minio, that we can read and use it to train the model later.
After this, we will deploy our flow and tasks into Prefect’s dashboard which we can monitor and schedule the flows and tasks.
Create a file deployment.py
In this file, we will deploy our flow with the flow data_processing into prefect’s UI, with the name data-preprocessing-customer-chrun , which is scheduled to run from Monday to Friday at 9 am in the morning. with the parameters param in deploy, it’s allows us to customize our workflow base on our use case. e.g. if we want to fill age with median instead we can assign to_fill_age_missing='median'.
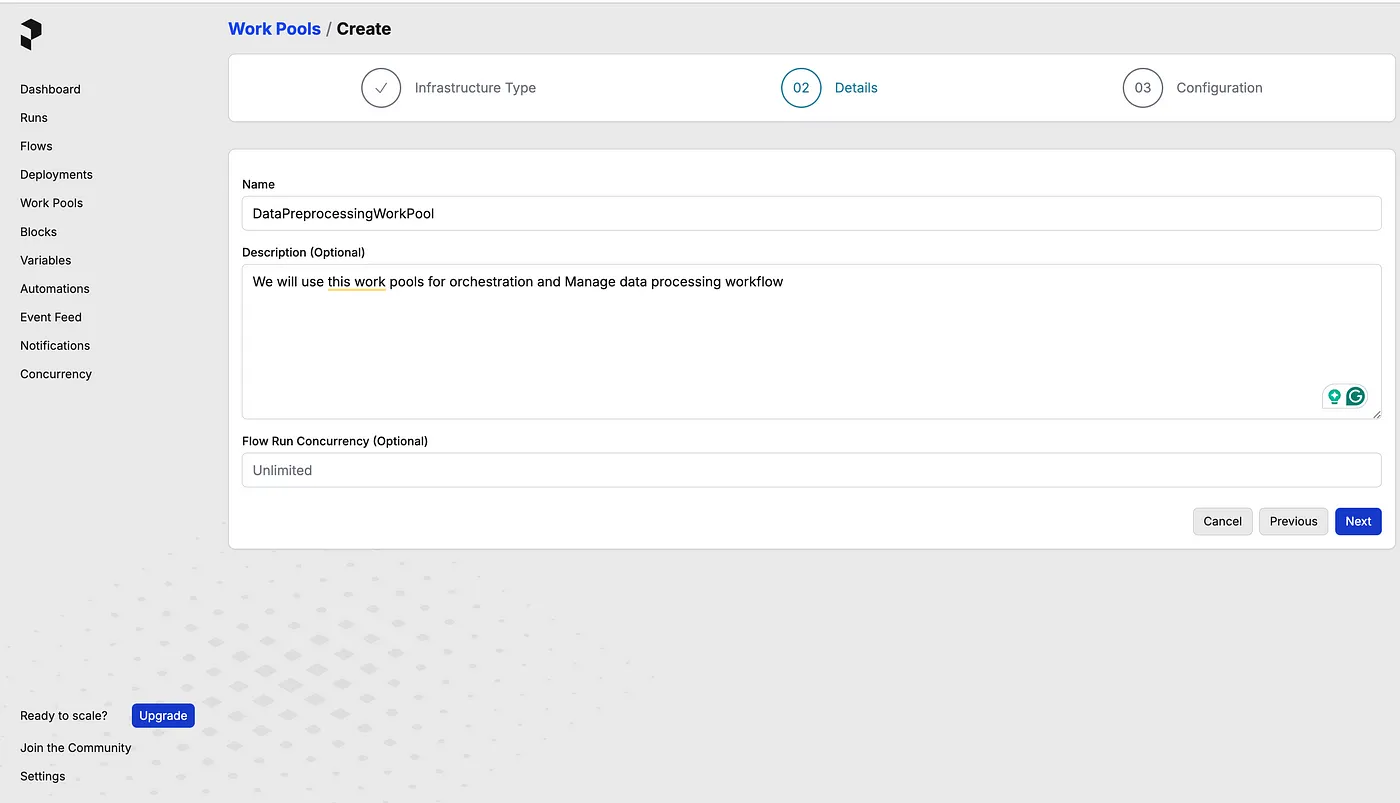
To deploy the flow, we need to create a work pool name DataPreprocessingWorkPool in the prefect’s dashboard.
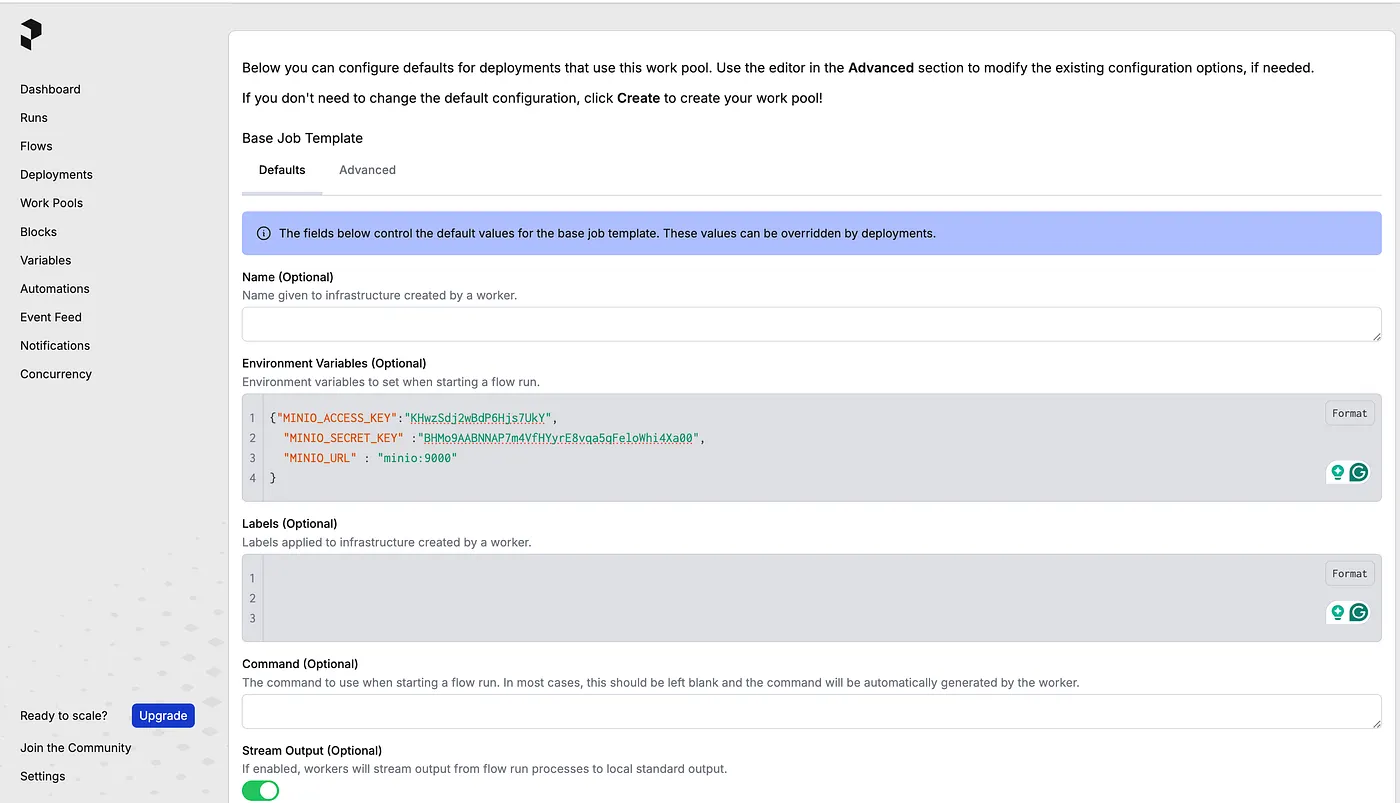
Also, Put some environment variables that we may use in our flow or tasks
{
"MINIO_ACCESS_KEY":"key generate from Minio",
"MINIO_SECRET_KEY" :"key genereate from Minio",
"MINIO_URL" : "minio:9000"
}
To deploy the flow you can run it in another docker container or run it in your local computer it will connect to the prefect’s server that you deploy in docker and establish your flow.
Run Using local Computer as Worker
prefect worker start -p DataPreprocessingWorkPool
Open another Terminal
python deployment.py
Run Using docker container as Worker
docker compose --profile worker start
After deploying your flow into Prefect’s server, you will be able to see your flow in Prefect’s dashboard
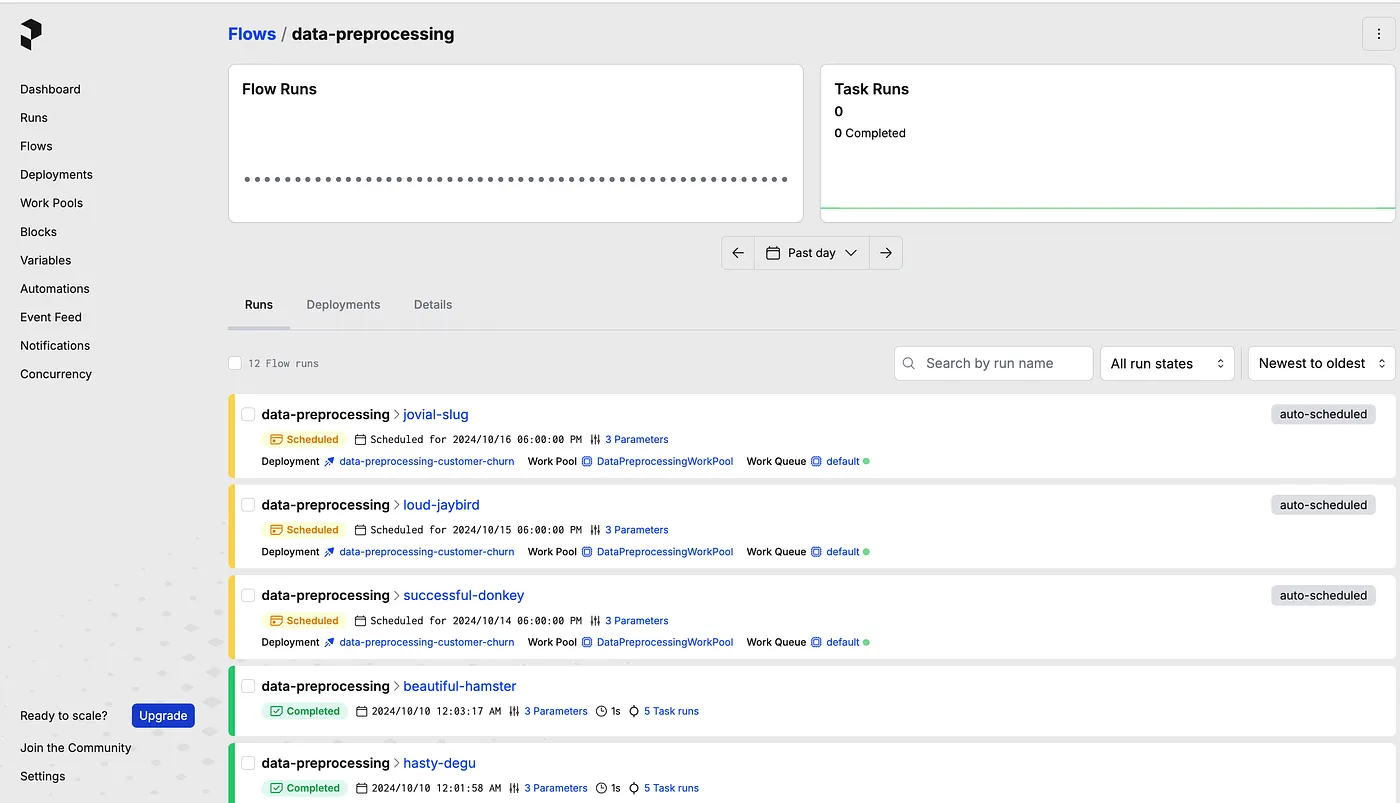
4. How Prefect Flow Orchestration Enhance Our Data Processing Workflow
4.1 Easy to Monitor
After we deploy our flow into the Prefect’s server, you can go to the prefect’s UI and monitor our flow runs in that UI with detail logs, time that it runs, time that it is scheduled to run.
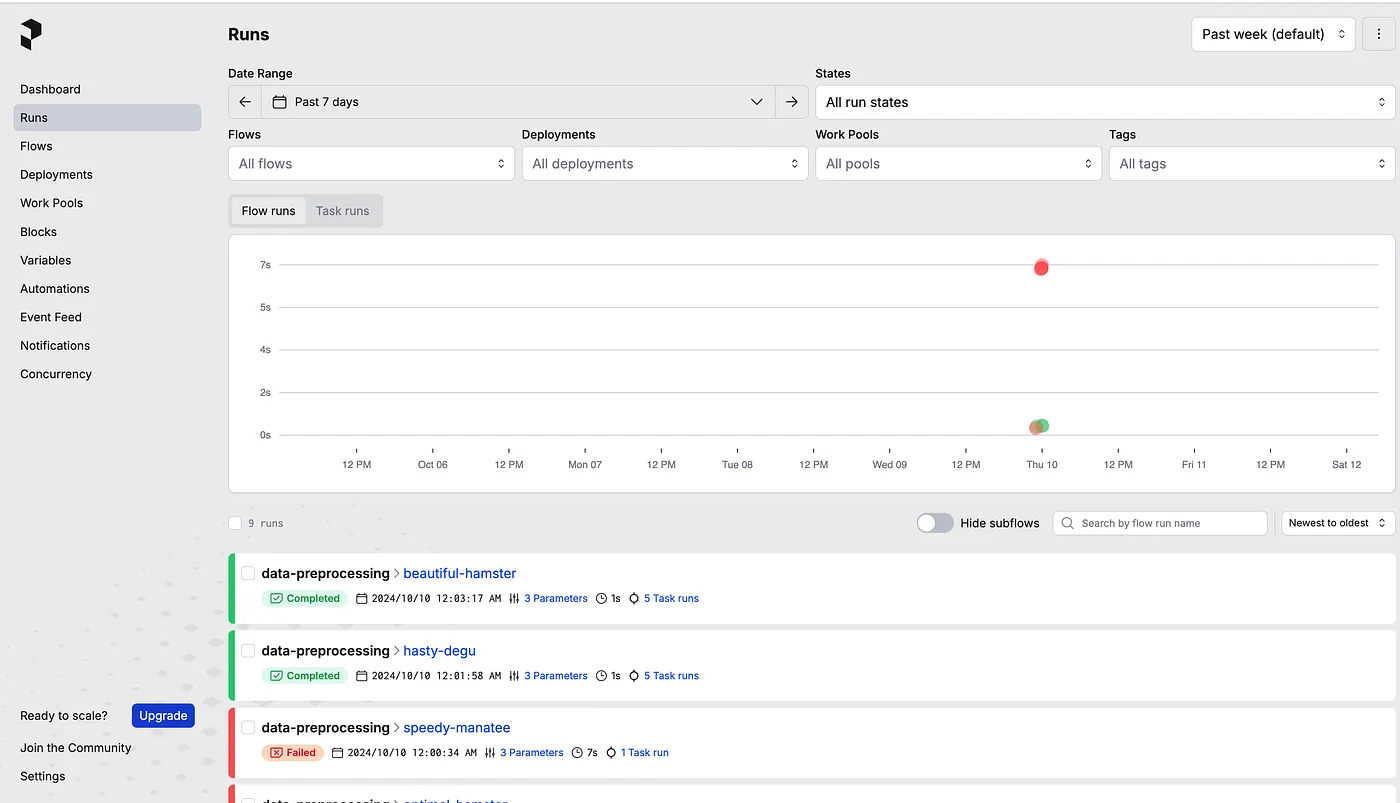
4.2 Easy to Schedule and Rerun the flow
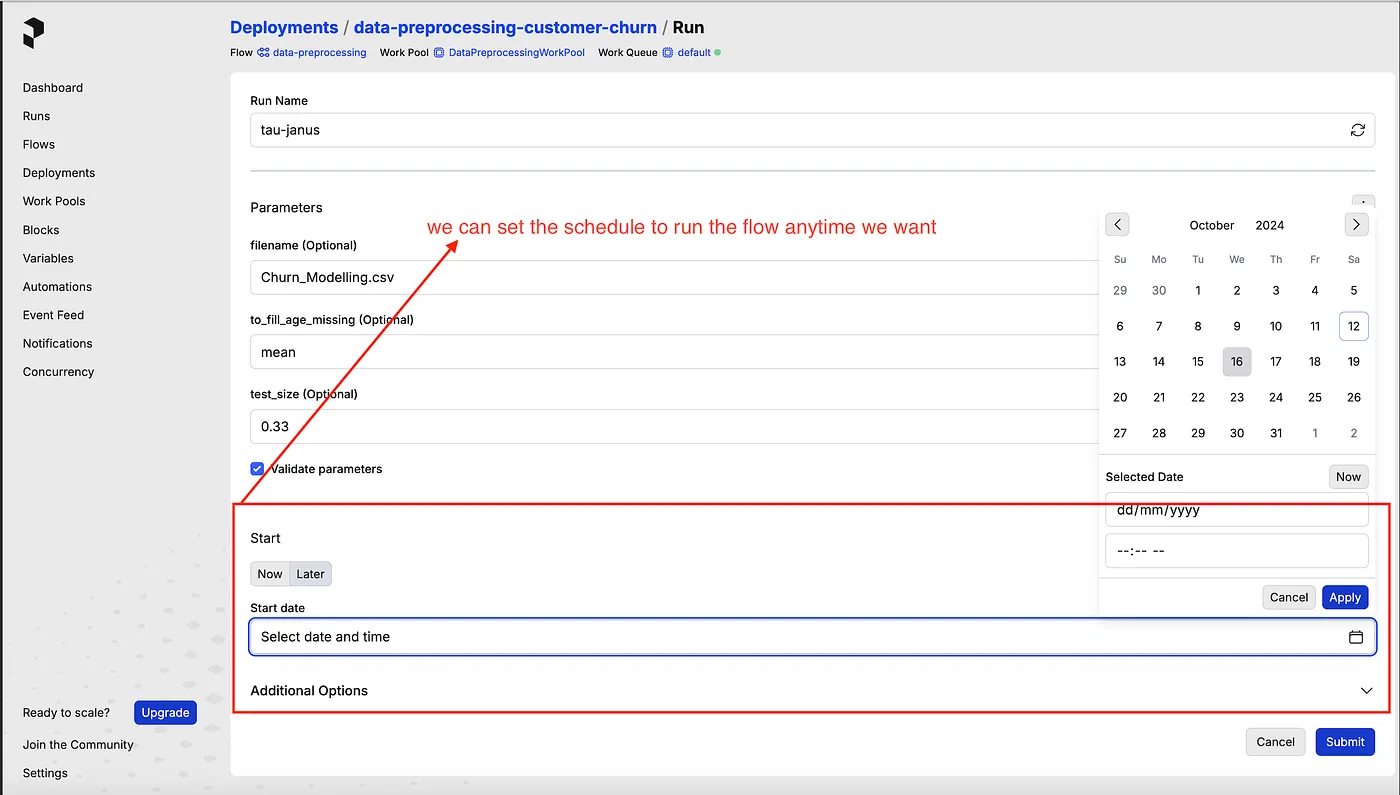
With Prefect, we will be able to schedule any flow to run on anytime we want without doing complicated code (we can do this in Prefect’s UI), also we can Rerun and debug the flow, or task anytime we want. For instance in machine learning data preprocessing we may want to schedule an update of our data in any period of time or have something to trigger, I think this will be perfect fit to use Prefect.
4.3 Each flow and task is customizable
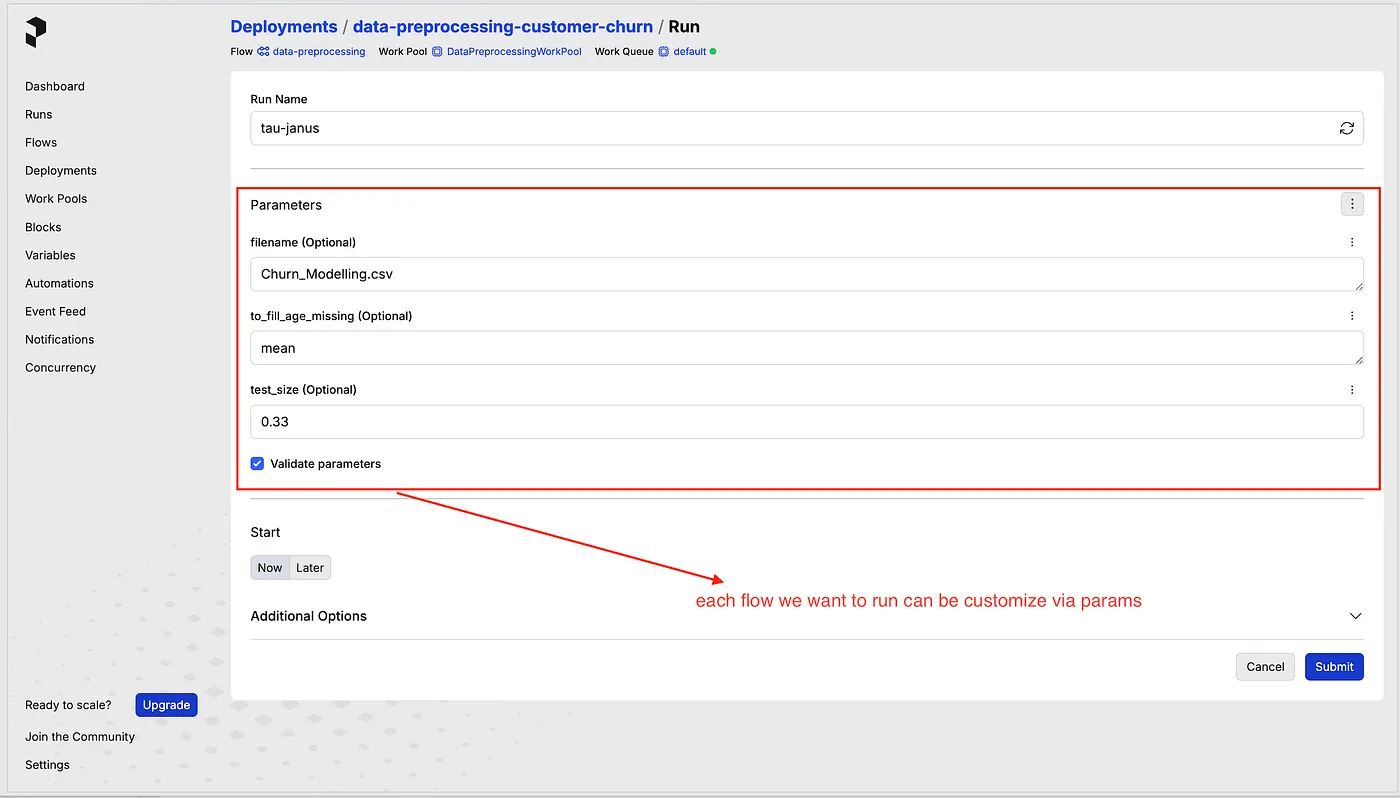
With Prefect we can set the parameter in UI when we run, so it will be easy for us to do keep changing the parameter for processing our data, e.g. in our case, we can change the value to fill into missing ages by mean or median base on the params that we pass to the flow. This will be very beneficial for our machine-learning workflow when we want to do experiment tacking.
What’s Next
Since in this part, we already doing data preprocessing, so after this, we will be able to use our data for training machine learning model for customer churn prediction, in the next part I will be focusing on
- Building machine learning
- Using Mlflow for the experiment tracking
- Using Evidently for Model Monitoring
Resource
- Minio : https://min.io/
- Prefect: https://docs.prefect.io/3.0/get-started/index
- Github Repo: https://github.com/seabnavin19/MlopsSeries/tree/part2.2